Rdd Reducebykey Count . the `reducebykey ()` method is a transformation operation used on pair rdds (resilient distributed datasets containing. for example, pair rdds have a reducebykey() method that can aggregate data separately for each key, and a join() method that can merge two rdds together by grouping elements with the same key. Reducebykey(func, numpartitions=none, partitionfunc=) reducebykey() example. Callable [ [v, v], v], numpartitions: Callable [ [k], int] = <function. val temp1 = temptransform.map { temp => ((temp.getshort(0), temp.getstring(1)), (1, usage_temp.getdouble(3))) }. In our example, we use pyspark reducebykey(). the reducebykey operation combines the values for each key using a specified function and returns an rdd of (key, reduced value) pairs. Optional [int] = none, partitionfunc: In our example, we can use reducebykey to calculate the total sales for each product as below:
from www.showmeai.tech
the `reducebykey ()` method is a transformation operation used on pair rdds (resilient distributed datasets containing. In our example, we can use reducebykey to calculate the total sales for each product as below: Optional [int] = none, partitionfunc: Callable [ [k], int] = <function. Reducebykey(func, numpartitions=none, partitionfunc=) reducebykey() example. In our example, we use pyspark reducebykey(). Callable [ [v, v], v], numpartitions: for example, pair rdds have a reducebykey() method that can aggregate data separately for each key, and a join() method that can merge two rdds together by grouping elements with the same key. val temp1 = temptransform.map { temp => ((temp.getshort(0), temp.getstring(1)), (1, usage_temp.getdouble(3))) }. the reducebykey operation combines the values for each key using a specified function and returns an rdd of (key, reduced value) pairs.
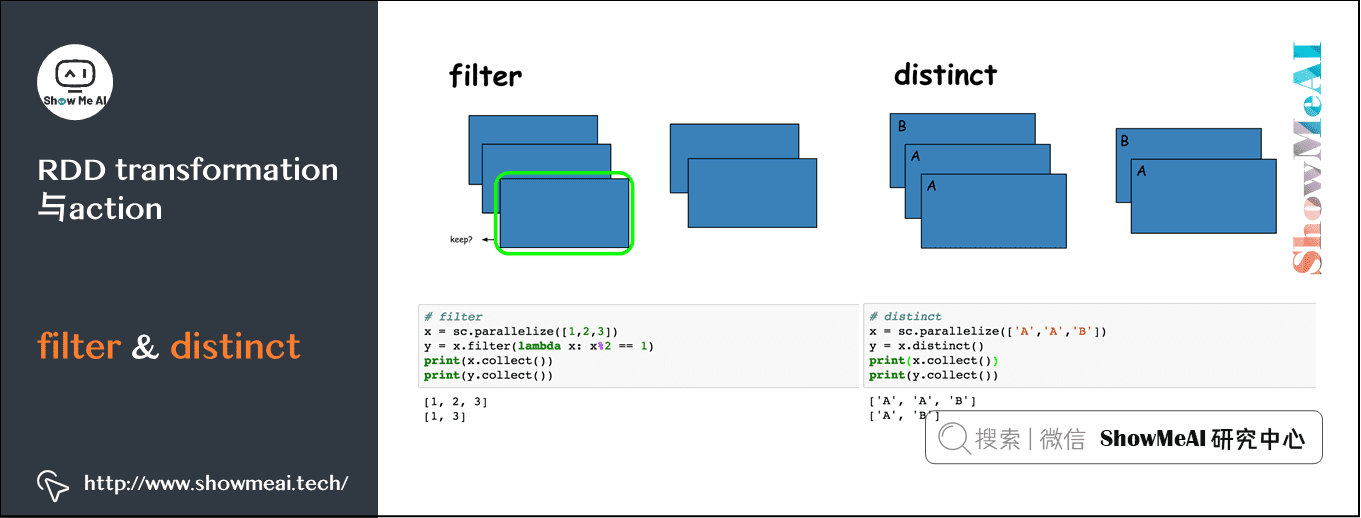
图解大数据 基于RDD大数据处理分析Spark操作
Rdd Reducebykey Count In our example, we can use reducebykey to calculate the total sales for each product as below: In our example, we can use reducebykey to calculate the total sales for each product as below: for example, pair rdds have a reducebykey() method that can aggregate data separately for each key, and a join() method that can merge two rdds together by grouping elements with the same key. Reducebykey(func, numpartitions=none, partitionfunc=) reducebykey() example. the reducebykey operation combines the values for each key using a specified function and returns an rdd of (key, reduced value) pairs. Optional [int] = none, partitionfunc: val temp1 = temptransform.map { temp => ((temp.getshort(0), temp.getstring(1)), (1, usage_temp.getdouble(3))) }. In our example, we use pyspark reducebykey(). Callable [ [k], int] = <function. Callable [ [v, v], v], numpartitions: the `reducebykey ()` method is a transformation operation used on pair rdds (resilient distributed datasets containing.
From www.youtube.com
RDD Advance Transformation And Actions groupbykey And reducebykey Rdd Reducebykey Count In our example, we use pyspark reducebykey(). In our example, we can use reducebykey to calculate the total sales for each product as below: the reducebykey operation combines the values for each key using a specified function and returns an rdd of (key, reduced value) pairs. Callable [ [v, v], v], numpartitions: Callable [ [k], int] = <function. Optional. Rdd Reducebykey Count.
From www.showmeai.tech
图解大数据 基于RDD大数据处理分析Spark操作 Rdd Reducebykey Count Reducebykey(func, numpartitions=none, partitionfunc=) reducebykey() example. the reducebykey operation combines the values for each key using a specified function and returns an rdd of (key, reduced value) pairs. In our example, we can use reducebykey to calculate the total sales for each product as below: val temp1 = temptransform.map { temp => ((temp.getshort(0), temp.getstring(1)), (1, usage_temp.getdouble(3))) }. Callable [. Rdd Reducebykey Count.
From blog.csdn.net
RDD中groupByKey和reduceByKey区别_groupbykey reducebykey区别CSDN博客 Rdd Reducebykey Count Callable [ [v, v], v], numpartitions: the reducebykey operation combines the values for each key using a specified function and returns an rdd of (key, reduced value) pairs. Reducebykey(func, numpartitions=none, partitionfunc=) reducebykey() example. the `reducebykey ()` method is a transformation operation used on pair rdds (resilient distributed datasets containing. val temp1 = temptransform.map { temp => ((temp.getshort(0),. Rdd Reducebykey Count.
From stackoverflow.com
scala Modified countByKey in spark Stack Overflow Rdd Reducebykey Count Callable [ [k], int] = <function. for example, pair rdds have a reducebykey() method that can aggregate data separately for each key, and a join() method that can merge two rdds together by grouping elements with the same key. the `reducebykey ()` method is a transformation operation used on pair rdds (resilient distributed datasets containing. Reducebykey(func, numpartitions=none, partitionfunc=). Rdd Reducebykey Count.
From www.showmeai.tech
图解大数据 基于RDD大数据处理分析Spark操作 Rdd Reducebykey Count the `reducebykey ()` method is a transformation operation used on pair rdds (resilient distributed datasets containing. Callable [ [k], int] = <function. In our example, we use pyspark reducebykey(). for example, pair rdds have a reducebykey() method that can aggregate data separately for each key, and a join() method that can merge two rdds together by grouping elements. Rdd Reducebykey Count.
From sparkbyexamples.com
PySpark RDD Tutorial Learn with Examples Spark By {Examples} Rdd Reducebykey Count the reducebykey operation combines the values for each key using a specified function and returns an rdd of (key, reduced value) pairs. the `reducebykey ()` method is a transformation operation used on pair rdds (resilient distributed datasets containing. In our example, we use pyspark reducebykey(). Reducebykey(func, numpartitions=none, partitionfunc=) reducebykey() example. for example, pair rdds have a reducebykey(). Rdd Reducebykey Count.
From blog.csdn.net
理解RDD的reduceByKey与groupByKeyCSDN博客 Rdd Reducebykey Count Callable [ [v, v], v], numpartitions: for example, pair rdds have a reducebykey() method that can aggregate data separately for each key, and a join() method that can merge two rdds together by grouping elements with the same key. Optional [int] = none, partitionfunc: the reducebykey operation combines the values for each key using a specified function and. Rdd Reducebykey Count.
From www.analyticsvidhya.com
8 Apache Spark Optimization Techniques Spark Optimization Tips Rdd Reducebykey Count the `reducebykey ()` method is a transformation operation used on pair rdds (resilient distributed datasets containing. In our example, we can use reducebykey to calculate the total sales for each product as below: In our example, we use pyspark reducebykey(). Callable [ [v, v], v], numpartitions: Callable [ [k], int] = <function. val temp1 = temptransform.map { temp. Rdd Reducebykey Count.
From blog.csdn.net
pyspark RDD reduce、reduceByKey、reduceByKeyLocally用法CSDN博客 Rdd Reducebykey Count the reducebykey operation combines the values for each key using a specified function and returns an rdd of (key, reduced value) pairs. Callable [ [v, v], v], numpartitions: Callable [ [k], int] = <function. val temp1 = temptransform.map { temp => ((temp.getshort(0), temp.getstring(1)), (1, usage_temp.getdouble(3))) }. In our example, we can use reducebykey to calculate the total sales. Rdd Reducebykey Count.
From justdodt.github.io
reduceByKey,groupByKey,count,collect算子 JustDoDT'sBlog Rdd Reducebykey Count In our example, we use pyspark reducebykey(). the reducebykey operation combines the values for each key using a specified function and returns an rdd of (key, reduced value) pairs. Optional [int] = none, partitionfunc: the `reducebykey ()` method is a transformation operation used on pair rdds (resilient distributed datasets containing. Callable [ [k], int] = <function. In our. Rdd Reducebykey Count.
From blog.csdn.net
rdd利用reducebykey计算平均值_reducebykey求平均值CSDN博客 Rdd Reducebykey Count In our example, we use pyspark reducebykey(). the `reducebykey ()` method is a transformation operation used on pair rdds (resilient distributed datasets containing. Callable [ [k], int] = <function. for example, pair rdds have a reducebykey() method that can aggregate data separately for each key, and a join() method that can merge two rdds together by grouping elements. Rdd Reducebykey Count.
From www.youtube.com
How to do Word Count in Spark Sparkshell RDD flatMap Rdd Reducebykey Count In our example, we can use reducebykey to calculate the total sales for each product as below: for example, pair rdds have a reducebykey() method that can aggregate data separately for each key, and a join() method that can merge two rdds together by grouping elements with the same key. Reducebykey(func, numpartitions=none, partitionfunc=) reducebykey() example. Optional [int] = none,. Rdd Reducebykey Count.
From www.youtube.com
53 Spark RDD PairRDD ReduceByKey YouTube Rdd Reducebykey Count Callable [ [v, v], v], numpartitions: In our example, we can use reducebykey to calculate the total sales for each product as below: Reducebykey(func, numpartitions=none, partitionfunc=) reducebykey() example. In our example, we use pyspark reducebykey(). Callable [ [k], int] = <function. for example, pair rdds have a reducebykey() method that can aggregate data separately for each key, and a. Rdd Reducebykey Count.
From stackoverflow.com
scala Modified countByKey in spark Stack Overflow Rdd Reducebykey Count Callable [ [v, v], v], numpartitions: Optional [int] = none, partitionfunc: In our example, we can use reducebykey to calculate the total sales for each product as below: In our example, we use pyspark reducebykey(). for example, pair rdds have a reducebykey() method that can aggregate data separately for each key, and a join() method that can merge two. Rdd Reducebykey Count.
From blog.csdn.net
Spark RDD的flatMap、mapToPair、reduceByKey三个算子详解CSDN博客 Rdd Reducebykey Count Optional [int] = none, partitionfunc: the reducebykey operation combines the values for each key using a specified function and returns an rdd of (key, reduced value) pairs. for example, pair rdds have a reducebykey() method that can aggregate data separately for each key, and a join() method that can merge two rdds together by grouping elements with the. Rdd Reducebykey Count.
From blog.csdn.net
理解RDD的reduceByKey与groupByKeyCSDN博客 Rdd Reducebykey Count In our example, we can use reducebykey to calculate the total sales for each product as below: the reducebykey operation combines the values for each key using a specified function and returns an rdd of (key, reduced value) pairs. In our example, we use pyspark reducebykey(). val temp1 = temptransform.map { temp => ((temp.getshort(0), temp.getstring(1)), (1, usage_temp.getdouble(3))) }.. Rdd Reducebykey Count.
From zhuanlan.zhihu.com
Spark编程笔记(2)RDD编程基础 知乎 Rdd Reducebykey Count the reducebykey operation combines the values for each key using a specified function and returns an rdd of (key, reduced value) pairs. val temp1 = temptransform.map { temp => ((temp.getshort(0), temp.getstring(1)), (1, usage_temp.getdouble(3))) }. Optional [int] = none, partitionfunc: for example, pair rdds have a reducebykey() method that can aggregate data separately for each key, and a. Rdd Reducebykey Count.
From blog.csdn.net
RDD 中的 reducebyKey 与 groupByKey 哪个性能高?_rdd中reducebykey和groupbykey性能CSDN博客 Rdd Reducebykey Count In our example, we can use reducebykey to calculate the total sales for each product as below: Callable [ [v, v], v], numpartitions: the reducebykey operation combines the values for each key using a specified function and returns an rdd of (key, reduced value) pairs. Optional [int] = none, partitionfunc: for example, pair rdds have a reducebykey() method. Rdd Reducebykey Count.